

OpenSpec:在 AI 協作開發中,先寫 Spec,再寫 Code
在這個 AI 協作開發的時代,當我在既有專案中開發新功能或除錯時,最常見的做法就是:把現有的 code 貼給 AI,描述一下問題,最後加一句「請幫我修正錯誤」或「請幫我生成功能」。
多數時候,AI 真的會產出一段看起來「像樣」的程式碼。運氣好一點,功能可以正常運作;運氣差一點,不只問題沒有解決,還順手把其他功能一起弄壞 😓
於是我開始抱怨 AI 不夠聰明、給的 code 不可靠。但後來想想,問題可能不完全在 AI,而是在我給它的需求與規格本來就不夠清楚。當需求與規格本身就模糊,產出錯誤的功能或程式碼,其實是一件再正常不過的事情。
更麻煩的是,即使運氣好功能正常運作後,我開始 review 程式碼時,卻發現整個 coding style 跟團隊的規範相差甚遠,為了符合團隊的規範,於是又得花更多時間修改。
以上大概是我過去使用 AI 工具寫程式時,遇到的種種狀況。
其實以上狀況在我使用 Claude Code 後,已經有了很大的改善,但還是遇到了一些問題。
例如我習慣在開發功能前先自己梳理需求並列點,一方面可以更清楚開發脈絡,另一方面也能讓容易分心且健忘的自己知道現在進行到哪一步驟。在執行前我也會先跟 Claude Code 好朋友確認一下執行邏輯,以及有沒有什麼邊界狀況需要考慮。有時候討論的太熱烈 token 不小心就燒完了 😅。
但這不是最大的困難,我自己覺得最大的困難是:這些步驟脈絡不管用圖形化或是寫在筆記,總之是寫成一個我可以理解的方式,但是當我需要跟同事解釋較複雜的邏輯脈絡時,這份我的筆記可能不夠清楚到可以讓人一看就懂。有時候我花更多的時間是在準備一份同事、客戶都看得懂的邏輯或規格書(當然這已經是請 AI 協助調整過的版本)。
雖然我自認為已經算是不那麼排斥寫文件的工程師了(畢竟是文組出身 🤔 )但我不得不承認,花大把的時間搞這些,有時候難免會有點小困擾。
以上的困擾基本上在我認識 OpenSpec 後,解決了八成以上(剩下的可能是 token 不夠用,開玩笑的)
OpenSpec 規格驅動開發 (Spec-Driven Development, SDD) 框架
如同我的標題所述 OpenSpec 就是一個讓你先寫規格 (Spec) 再寫程式碼 (Code) 的工具。
值得一提的是,OpenSpec 的設計理念是
“built for brownfield, not just greenfield”
代表它不只適用於全新專案,更適合加入現有的專案中。這對於需要在既有系統上開發新功能的情境來說,非常實用,我下面的範例也是在我既有的專案中加入使用 OpenSpec。
流程
它會根據你的需求產生 Proposal (提案),這個提案包含完整的規格文件 (proposal → specs → design → tasks),接著可以根據這個 Proposal 去 Apply (應用),也就是讓 AI 根據步驟去撰寫程式碼,最後完成後將剛剛的提案 Archive (歸檔)存成專案文件。

這是最理想的狀態,但理想很豐滿現實很骨感。實務上我們很常在開發中發現「這邊邏輯需要修改一下」的狀況,所以更多時候是遇到在 Apply 步驟但卻需要回去修改 Proposal 的文件,根據我的圖示可以看到舊版是一個單向的流程,我們不能走回頭路。
不過這個問題現在已經被修正了!新版的 OPSX 工作流程變成可逆的,隨時可以滾動式調整,彈性更高:

文件分類
剛剛上面有提到,現在 continue 會依序建立需要的文件 (proposal → specs → design → tasks),這四個文件分別代表:
| 文件 | 意思 | 解釋 |
|---|---|---|
| proposal.md | 變更提案 | WHY 為何要做這個功能 |
| specs.md | 規格 | WHAT 這個功能要做什麼內容 |
| design.md | 技術設計 | HOW 應該要怎麼執行 |
| tasks.md | 執行任務 | TODO LIST 執行內容的待辦步驟清單 |
📍 注意:這些文件的建立是有順序性的。其實看解釋應該不難理解 —- 我需要先知道「為何要做」(WHY),才能知道「要做什麼」(WHAT),接著才能規劃「怎麼執行」(HOW),最後才是列出「執行的待辦清單」(TODO LIST)。
執行指令
| 指令 | 意思 |
|---|---|
/opsx:explore |
在正式開始變更前,先與 AI 討論想法、調查問題或比較方案。當想法逐漸清晰後,可以轉換到 /opsx:new 或 /opsx:ff |
/opsx:new |
開啟一個新需求的資料夾,並準備開始建立規格文件 |
/opsx:continue |
基於新開啟的需求,依序建立下一個文件 |
/opsx:ff |
已經很清楚知道需求,可以用此一次建立所有需要的文件(/opsx:new + /opsx:continue 的濃縮版) |
/opsx:apply |
根據 tasks.md 開始依序執行任務,並根據需要更新文件(類似舊版 /openspec:apply) |
/opsx:sync |
預覽規格合併的結果( 選用,因為 archive 本來就會自動合併) |
/opsx:archive |
將已經處理完成的任務內容,儲存成歸檔狀態(類似舊版 /openspec:archive) |
💡 快速理解:
- 需求不明確? 用
/opsx:explore先討論 - 需求明確? 用
/opsx:ff快速建立 - 想逐步確認? 用
/opsx:new+/opsx:continue慢慢來 - 執行中發現問題? 直接編輯所有文件後,繼續執行
/opsx:apply
新舊版對應:
- 舊版
/openspec:proposal≈ 新版/opsx:ff - 舊版
/openspec:apply≈ 新版/opsx:apply - 舊版
/openspec:archive≈ 新版/opsx:archive
指令流程 & 新版舊版比較圖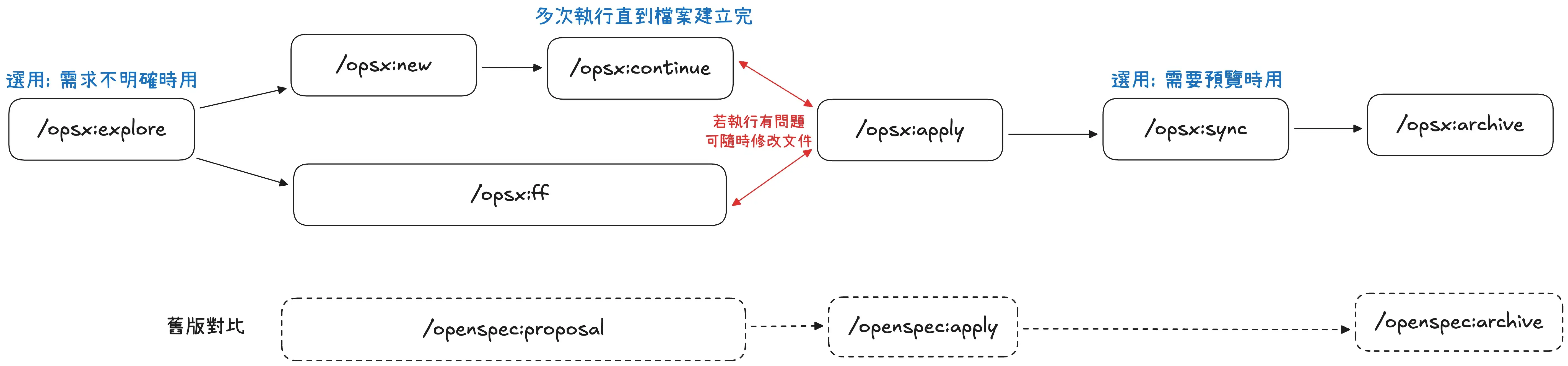
📍 注意:圖片中我雖然把 /opsx:explore 放在最前面,但是事實上在執行中若隨時有問題都可以用 /opsx:explore 開啟討論
實際使用案例
首先根據 官方文件 安裝 OpenSpec,並依提示選擇你慣用的 AI 工具。
我拿之前做的 使用 Ruby on Rails 串接 LINE 快速構建心理測驗 專案來示範。這次我想新增「分類功能」,但需求還不夠明確,所以先用:
/opsx:explore
然後開始描述需求:
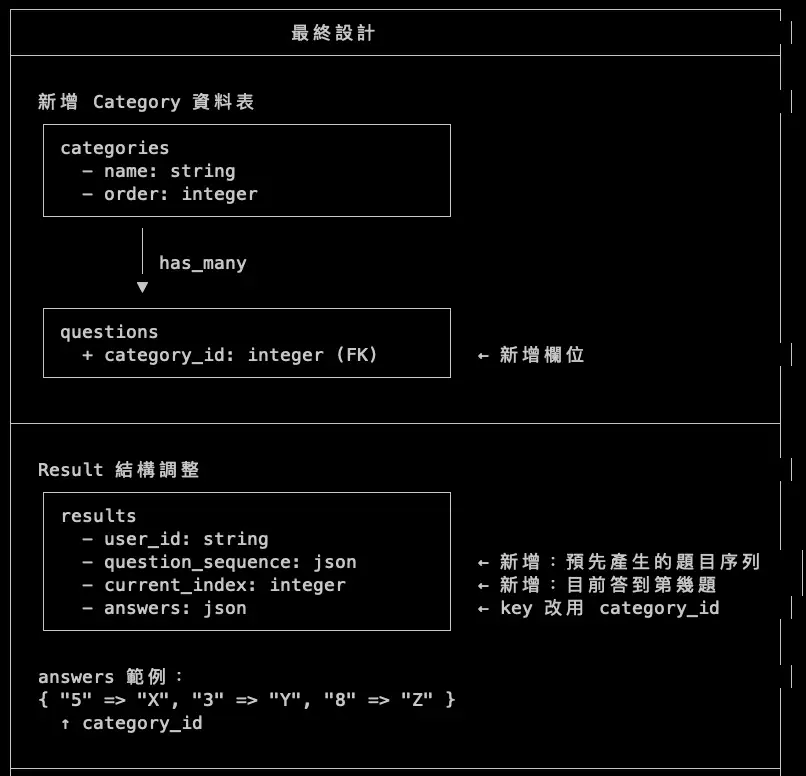
我希望可以新增分類資料表,內有欄位分類名稱(string)、順序(int),並且一個分類可以有很多問題,在建立 question 時就可以選擇分類,並且在 line_bot_controller.rb 的 start_test 原本是傳 questions.first 進去 send_question_to_user 作為第一題,現在因為有分類了我希望是隨機的,只要每個分類有各出現一題就好,雖然說出的題目跟順序是隨機的,但是我希望我的答案 result 原本是回傳 reply_message(event[‘source’][‘userId’], “您的測驗結果是#{result.answers.values.join}”) 但我現在希望是根據我在分類的順序顯示答案,例如分類有 A、B、C,順序分別是 1、2、3,那麼答案就會是 A 分類的答案接著 B 分類的答案最後 C 分類的答案串接起來顯示
我自認為需求已經算清楚了,但它依然開啟了下面的討論 — 像是一個確認需求的過程:


它問了我三個關鍵問題:
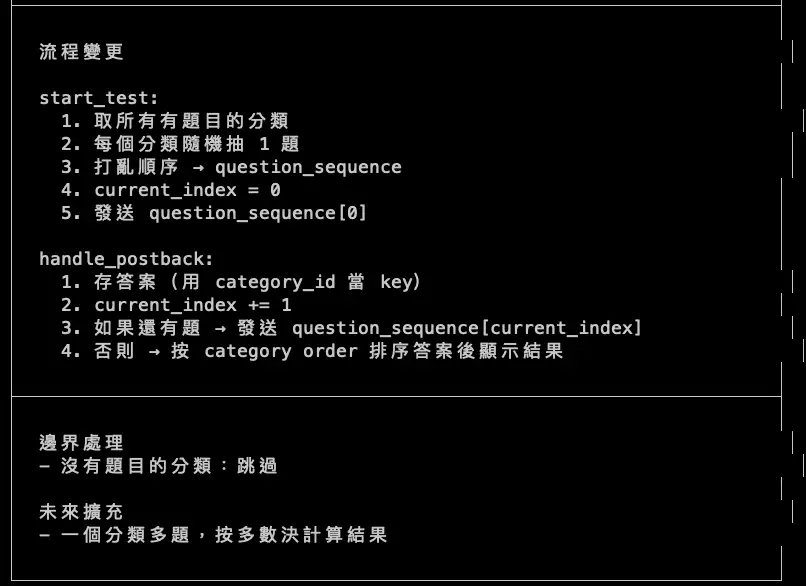
- 題目順序的「隨機」程度? — 確認我說的「隨機」具體是什麼意思
- 如何追蹤測驗進度? — 提供兩個方案讓我選擇
- 答案怎麼存? — 分析三種存法的 tradeoff
甚至連邊界狀況都問到:「如果某個分類沒有題目,要怎麼處理?」
第一次用的時候蠻驚豔的 — 它不只會提問,連選項都幫我列好了。在一來一回的討論後,需求逐漸清晰:
/opsx:ff
📍 注意:因為前面有先 /opsx:explore,所以這邊可以直接用 /opsx:ff,它會自動根據討論內容命名資料夾並建立相關文件。若沒有前面的討論,建議帶上名稱 /opsx:ff add-category-to-questions,它會先跟你確認需求再建立文件
此次 /opsx:ff 生成了以下檔案
openspec/changes/add-category-to-questions
├── design.md
├── proposal.md
├── specs
│ ├── category-based-testing
│ │ └── spec.md
│ └── category-management
│ └── spec.md
└── tasks.md
確認沒問題後我就開始執行
/opsx:apply
它會依據 tasks.md 逐一執行任務,完成後自動勾選。確認功能沒問題後,執行歸檔:
/opsx:archive
就這樣看起來其實已經很完整了,但在我開 server 要新建分類時,發現此次內容並沒有包含分類的 CRUD 以及在問題表單內加上選擇分類的欄位,之類的小問題,回去看我當初的需求確實沒提到這塊,不過這都是簡單的小問題,我就直接手動解決了,整體使用體驗還是非常舒適流暢的。
硬要說一個小缺點的話,就是在終端機裡讀這些 .md 檔不太美觀。不過這個問題被龍哥做的小工具 Spectra 解決了 — 加入專案後就能用圖形介面即時瀏覽和編輯這些文件,體驗好很多!
如果對這個小工具有興趣,可以參考龍哥的文章 Spectra:給 OpenSpec 的圖形介面,裡面有附上 App 下載連結。
結語
回顧整個使用過程,OpenSpec 最大的價值不只是「讓 AI 幫你寫 code」,而是在寫 code 之前,先把需求和設計想清楚。透過 /opsx:explore 的來回討論,很多邊界情況和設計決策在動手前就被釐清了,減少了後續修改的成本。
對我來說,這套流程解決了兩個痛點:
- 跟 AI 協作時需求不夠明確導致產出品質不穩定。
- 開發完還要另外整理文件給同事看 — 現在這些
.md檔在開發過程中就產出了,直接就能說明功能邏輯。
如果你也有類似的困擾,不妨試試看使用 OpenSpec 規格驅動開發的方式搭配 Spectra。